Where to store your data in 2023?
Original Title: Où stocker ses données en 2023 ?
A good recap of the current database landscape, with a bit of history to explain how we got here.
The question being: what database should I choose for my data, the answer is inevitably: it depends.
The talk goes through the history of DB, from the relational introduction to the advent of NoSQL and the “Relational Strikes Back” with the NewSQL. The main points being:
- the need for being distributed paved the road to NoSQL and new Data Models
- relational database are borrowing some tricks from NoSQL
- we have more choice than ever, so “choose wisely”
Some criteria to consider
- OLTP vs OLAP
- Architecture -> performance and resiliency
- Dev experience
- Security
- Devops (e.g. Terraforming)
- Availability of people who know how to do it, and also attracting talents
- Governance: financial cost, and how tight would I be to a provider
History of DBs
- Relational: starting in the 70s
- Object DB: dead before 2000, because that time applications were communicating using DBs, then the Internet happened
- NoSQL, which stands for Not Only SQL: vastly successful, also because of the many models it generically refers to:
- key-value
- document
- wide column store
- graph
Why did you choose a DB?
Wrong answers only:
- I have used it before - I confess I don’t really thing this is a wrong answer
- I have heard good things about it
- We have enterprise licenses for it
- It is free (as in free beer)
Personal note. I do not think reason 1 and 3 are that wrong: given that you are using the right model, knowing how to use is not a bad reason to choose it. Same goes for the enterprise licenses: it likely means you already have access to experts, solution architects and support. Of course one should not choose a very wrong DB like insisting with Oracle when your data model is document oriented.
The CAP Theorem
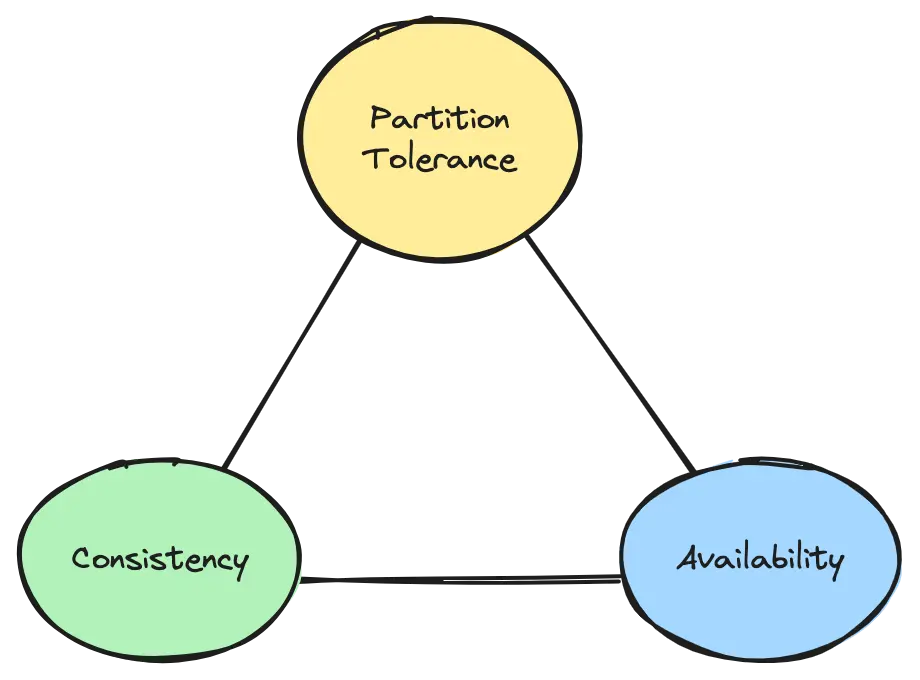 This is well known, yet not publicised enough. Repetita iuvant. The gist of it is: you can only have two.
This is well known, yet not publicised enough. Repetita iuvant. The gist of it is: you can only have two.
Partition Tolerance, the ability of continue to work in presence of network partitions, for example when there is a communication failure. toNoSQL has it and Relational don’t Consistency, which is the ability to read the last version from all the nodes Availability, the possibility to answer quickly
The BASE
I didn’t know about the BASE acronym: Basically Available Soft state, Eventually consistent. It’s now my favourite .
Here it’s the Eventually Consistent that makes you have the Partition Tolerance and the Availability from the CAP Theorem. To use the common example of the bank transfer: this would mean that when you transfer money from account A to account B, there is a moment when you see the money gone from A and not yet accredited on B. (Not saying this is good, it’s what happens with the Eventually consistent.)
NoSQL, Relational and the Advent of NewSQL
So, is NoSQL the only good choice? In 2010’s it was still a young technology, also because developers didn’t know how to use it. Now it’s mature and we know well how to model the data and how to use it. For the context: if the DB goes down, Decathlon would have a loss of 8K€ per minute.
In 2015 we saw the NewSQL, Relational but Distributed. They are usually proprietary, made for huge amount of data, cumbersome to deploy. But it’s to say that Relational Databases are not dead and they are borrowing a few tricks from the NoSQL world like distribution and sharding, aiming at defying the CAP theorem and provide all three criteria.
And one has also to consider that over the decades they have been over-optimised. This is also my experience, especially when running complex queries.
Notable Choices at Decathlon
- Relational -> PostgresSQL (which is moving towards the NewSQL with sharding and distribution)
- Key-value -> Redis, HazelNut
- Document -> MongoDB (Consistent by default since v6.0) and Couchbase
- Graph -> Neo4j
- NewSQL -> PostgreSQL, but actually it depends
Some personal notes
One of the talks I enjoyed the most, also because of my current role. I would personally recommend going through it to get a picture of the current DB landscape. The good being: there are many choices and it would be a pity to choose one solution without considering what’s best for the data model you will work with.
More details and the slides (mostly in English) can be found here and here. The talk was delivered by Ciryl Gambis, Staff Software Engineer at Decathlon.
https://rivieradev.fr/session/1129