SparkSession autocomplete in IntelliJ
I really enjoy working with the spark-shell. It provides a quick way to experiment with code snippets. However, there are times when you might prefer to write those snippets in a proper file and have access to syntax checks and highlighting.
Personally, I use IntelliJ, but you should be able to adapt this example to your preferred IDE.
Once you have created your script file, you can add the following code at the beginning of the file:
1
2
3
4
5
6
7
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Spark shell")
.config("spark.sql.warehouse.dir", "file:/tmp/spark-warehouse")
.master("local")
.getOrCreate()
import spark.implicits._
The first two lines are used to create a SparkSession object. The spark-shell creates it for you, but you don’t have it (yet) when writing in IntelliJ. It basically creates this object so that IntelliJ does not complain too much about the syntax, and you have all the auto-completions that a good CTRL+Space can give you. On the other hand, when you use this file in the spark-shell, the spark object you created will be kindly ignored in favor of the local instance. It’s not exactly like this, but the effect is pretty much the same.
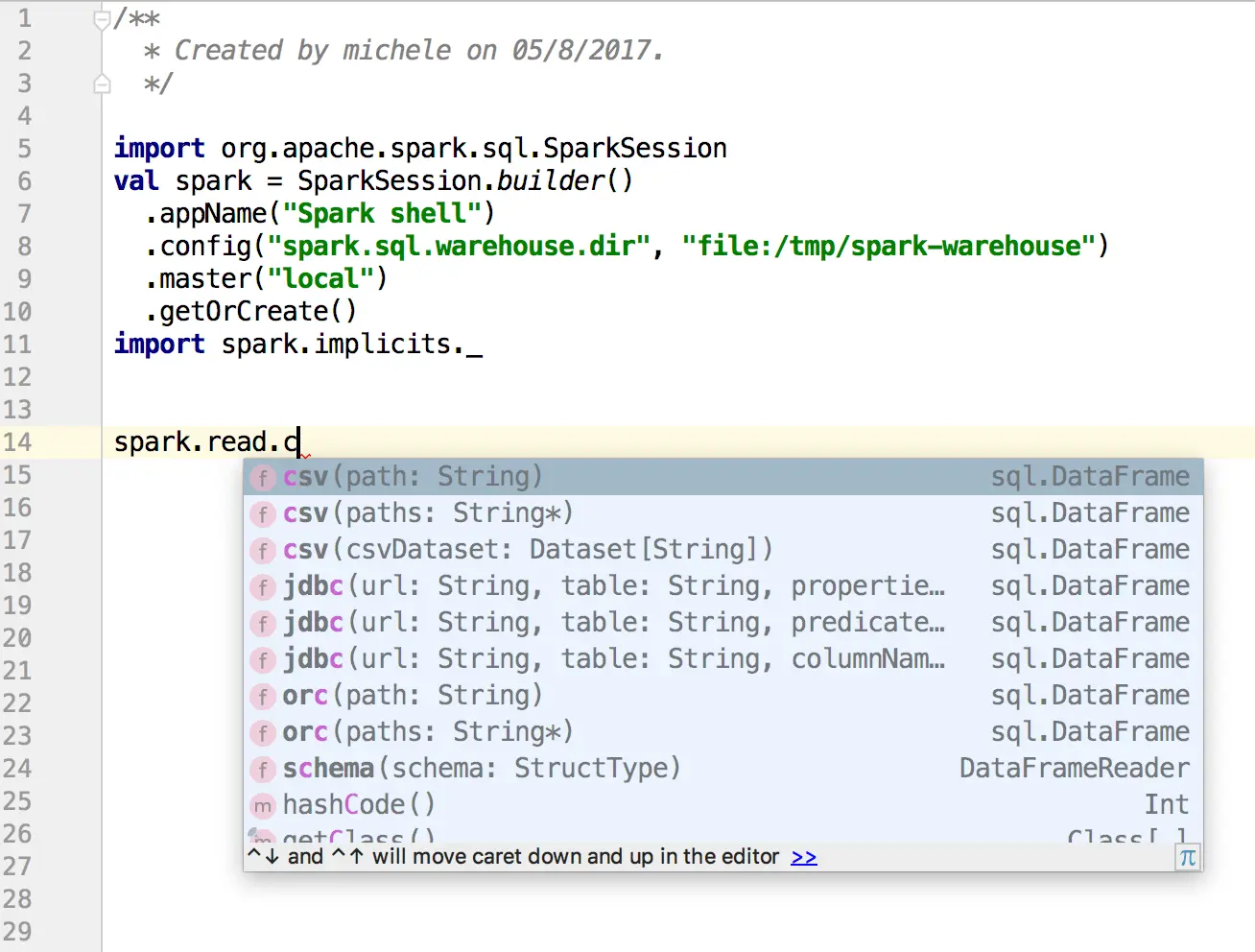
The import spark.implicits._ allows you to use in IntelliJ all the implicit conversions provided by spark on top of the native types of scala (thanks to the scala Implicits. For example, you can write:
1
2
val myList = "Michele" :: "Maggie" :: "Vincenzo" :: "Luca" :: Nil
val myDF = myList.toDF
despite the fact that the List type in scala has no toDF method.
Update 2023-08-12. This post has been imported from my previous neglected blog.