FoundationDB: the best kept secret of new distributed architectures - Talk report
Original title: FoundationDB : le secret le mieux gardé des nouvelles architectures distribuées !
Here are some more notes from the talk by Pierre Zemb at Riviera DEV 2023. My full trip report is here, part one and here, part two.

An introductory talk about FoundationDB, which to be honest I only heard about a few days before for totally unrelated reasons.
The gist of it is that FoundationDB is a storage engine stripped down to the bone and putting all the effort to reach:
- ease of scaling out
- ease of building up abstractions
- ease of operations, and
- high performances.
The Concepts of FoundationDB
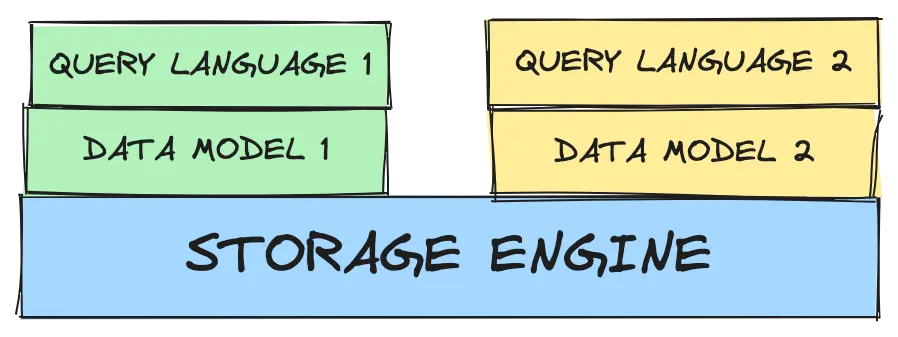
- Transactions but NoSQL performance and scale
- Reduce core to minimal feature set
- Add feature back with higher-level abstractions called Layers
The set of features is so reduced that not even authentication is implemented, but has to be provided via modules.
Thanks to the ease of building up abstractions, a single storage engine can be adapted to different Data Models and different Query Languages.
The core storage is based on ordered key-values, it’s very fault tolerant also because each process has the same isolation level as the spawner.
FoundationDB is open source, but it has not always been like this:
- 2009: FoundationDB is founded
- 2012: FoundationDB launches its distributed multi-model database
- 2015: Apple acquires FoundationDB, leading to the temporary suspension of the product’s availability to the public.
- 2018: Apple open sources FoundationDB under the Apache 2.0
Along with Apple, SnowFlake is the other huge user of FoundationDB, and there is a strong cooperation between the two companies for its development.
Actors at scale
FoundationDB is actor based, and to scale out you can increase the number of roles. It’s actually the DB itself that will tell you how many roles you need to deploy. You won’t do this at production time, but rather during benchmark sessions.
Rock Solid Simulation
One of the most interesting thing about FoundationDB is the approach used for its development: a simulator was developed before developing the actually database. This choice was dictated by the experience that the founders, Nick Lavezzo, Dave Rosenthal and Dave Scherer, had when debugging distributed systems.
The simulator is able to inject errors, like disk and network errors, and each simulation can be replayed deterministically.
It’s said that Apple and SnowFlake together have already accumulated 4000 years of simulations!
FoundationDB @Apple
Something I didn’t know, and didn’t imagine: FoundationDB is used to handle the whole iCloud, and each user has a virtualized mini database. My owe is strongly mitigated by the not so stellar performances of iCloud which I guess is mostly due to some poor choice in the synchronization compartment.
FoundationDB @SnowFlake
- Used for any (internal) transactional workload
- It has become the critical component of their architecture
- They value robustness over performance.
Clever Cloud
The talk was delivered by Pierre Zemb of Clever Cloud. They are building a Serverless Product in Rust. Of course it’s a DB, of course it’s based on FoundationDB. The 50 people in the company have also added some rust code in the FoundationDB simulator to test some real incident situations and ensure the product will be solid in Production.
Transactions
Transactions are handled with versioning 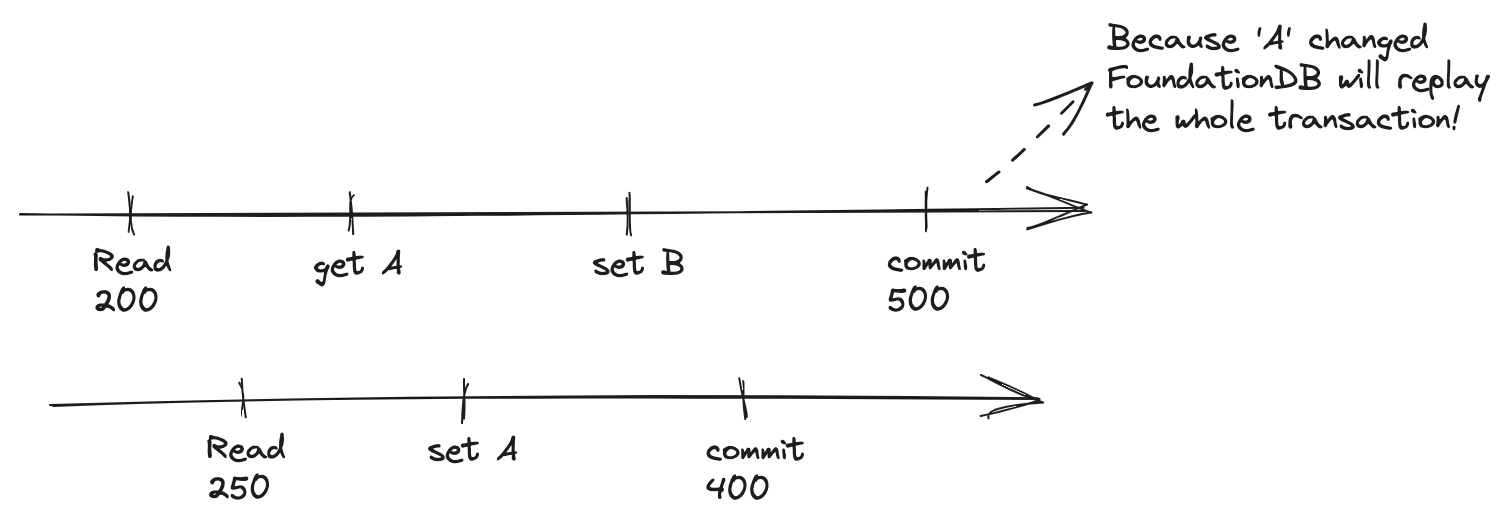
The FoundationDB Resolver remembers the whole history for 5 seconds. Which is also an obvious limitation: no transaction can last more than 5 seconds.
Conclusions
| Pros | Cons |
|---|---|
| For Ops, it’s robust and scalable | Still a distributed system |
| For Devs, framework to build layers | Very young and small community |
| Support for many languages | No clients as good as the Java one |
| One does not simply deeply FoundationDB |

The talk was delivered on 2023-07-11 by Pierre Zemb of Clever Cloud. It was in French.
You can read more in his post Notes about FoundationDB.